


Build your own Transformer Model from Scratch using Pytorch
Learn how to build a Transformer model using PyTorch.


Introduction
Transformers are like the superheroes of the computer world, especially when it comes to understanding human language. They're super smart models that can handle tasks like translating languages or summarizing texts. What makes them so special? Well, it's all about their attention superpower.
Imagine you're reading a sentence. Your brain automatically pays attention to certain words based on their importance to understand the meaning, right? That's what Transformers do too! They use something called 'self-attention' to focus on important parts of the input.
Think of it like this: if you're translating a sentence, you'd focus more on words that help you understand what the sentence means. Transformers do the same thing but in a super-fast and efficient way.
This 'self-attention' superpower is what makes Transformers so good at handling long sentences and understanding tricky language stuff. It's like having a super smart buddy who knows exactly what parts of the sentence are important to get the message across.
So, in this tutorial, we're going to learn how we can build our very own transformers using PyTorch. Excited? Let's get started!
Note: This article focuses on implementation rather than theory. To delve deeper into the theory behind large language models, check out this playlist.
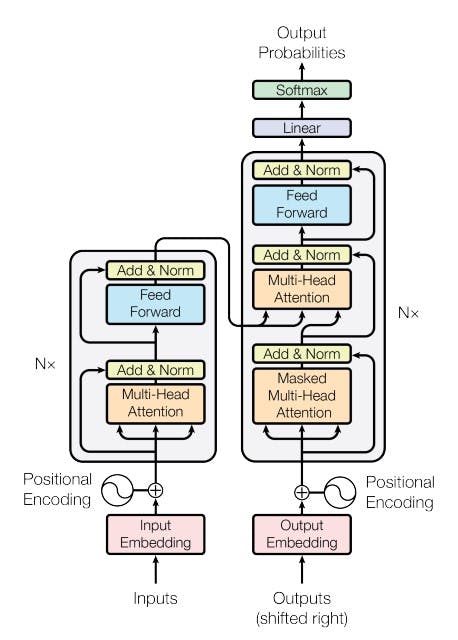
The Transformer model has a structure where self-attention and fully connected layers are stacked together in both the encoder and decoder. This architecture is depicted in the above figure, with the left side showing the encoder and the right side showing the decoder.
Importing the necessary libraries
We'll start coding part by importing the PyTorch library for core functionality and the neural network module for creating neural networks. Also, we will import the standard Python math module for mathematical operations.
import torch
import torch.nn as nn
import math
After importing the necessary libraries, the first part that we will be building is input embeddings (refer the model architecture at top).
Input Embeddings
In the architecture you can see that the input embeddings take the input and convert into an embedding. Let's code it.
class InputEmbeddings(nn.Module):
def __init__(self, d_model, vocab_size):
super().__init__()
self.d_model = d_model
self.vocab_size = vocab_size
self.embedding = nn.Embedding(vocab_size, d_model)
def forward(self, x):
return self.embedding(x) * math.sqrt(self.d_model)
In the above code, I have defined a class called InputEmbeddings, which is responsible for converting input tokens into continuous vector representations. I am using PyTorch's Embedding module for this purpose.
The constructor (init) takes two parameters: d_model, representing the dimensionality of the embedding vectors, and vocab_size, indicating the size of the vocabulary.
The forward method of this class simply applies the embedding layer to the input tensor x, mapping each token to its corresponding embedding vector. Additionally, I am scaling the embedding vectors by multiplying them with the square root of d_model. Why? Because, to stabilize the gradients during training. It helps to prevent the gradients from becoming too small or too large, which can lead to issues like vanishing or exploding gradients.
The next module that we are going to build is the positional encoding (refer the model architecture at top).
Positional Encoding
Alright, so we've got our input embeddings all set up. Now we're going to add what we call "positional encoding" to our input embeddings. Why? Because transformers don't have a built-in sense of position like humans do when we read sentences. So, we need to give our model a way to understand where each word or token is in a sequence. Let's code it.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, seq_len, dropout):
super().__init__()
self.d_model = d_model
self.seq_len = seq_len
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(seq_len, d_model)
# Create a vector of shape (seq_len,1)
position = torch.arange(0, seq_len, dtype=torch.float).unsqueeze(1)
# Create a vector of shape (d_model)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# Apply sine to even indices
pe[:, 0::2] = torch.sin(position * div_term) # sin(position * (10000 ** (2i / d_model))
# Apply cosine to odd indices
pe[:, 1::2] = torch.cos(position * div_term) # cos(position * (10000 ** (2i / d_model))
# Add a batch dimension to the positional encoding
pe = pe.unsqueeze(0) # (1, seq_len, d_model)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + (self.pe[:, :x.shape[1], :]).requires_grad_(False) # (batch, seq_len, d_model)
return self.dropout(x)
In this code snippet, the constructor (init) takes three parameters: d_model (the dimensionality of the input embeddings), seq_len (the maximum sequence length), and dropout (the dropout probability). Inside the constructor, we initialize the parameters and calculate the positional encoding values based on the position and dimensionality of the embeddings. To understand the formula in more detail watch this tutorial.
The forward method applies the positional encoding to the input embeddings by adding the positional encoding values to the input embeddings. It then applies dropout to the resulting tensor to prevent overfitting during training.
The next module that we are going to build is the multi head attention (refer the model architecture at top).
Multi Head Attention
Alright, now that we've got our input embeddings with positional encoding sorted, let's talk about attention. Imagine you're reading a sentence, and your brain automatically focuses on certain words that are important for understanding the meaning, right? Well, that's exactly what attention does in our Transformer model. But here's the twist: instead of just one attention mechanism, we're going to use multiple heads of attention.
This multi-head attention is like having different experts in our model, each focusing on different aspects of the input. Some might focus on the meaning of words, while others might pay attention to the order of words or their relationships with each other. Let's code it.
class MultiHeadAttentionBlock(nn.Module):
def __init__(self, d_model, h, dropout):
super().__init__()
self.d_model = d_model
self.h = h
assert d_model % h == 0, "d_model is not divisible by h"
self.d_k = d_model // h
self.w_q = nn.Linear(d_model, d_model, bias=False)
self.w_k = nn.Linear(d_model, d_model, bias=False)
self.w_v = nn.Linear(d_model, d_model, bias=False)
self.w_o = nn.Linear(d_model, d_model, bias=False)
self.dropout = nn.Dropout(dropout)
def attention(query, key, value, mask, dropout: nn.Dropout):
d_k = query.shape[-1]
# (batch, h, seq_len, d_k) --> (batch, h, seq_len, seq_len)
attention_scores = (query @ key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
attention_scores.masked_fill_(mask == 0, -1e9)
attention_scores = attention_scores.softmax(dim=-1) # (batch, h, seq_len, seq_len) # Apply softmax
if dropout is not None:
attention_scores = dropout(attention_scores)
# (batch, h, seq_len, seq_len) --> (batch, h, seq_len, d_k)
# return attention scores which can be used for visualization
return (attention_scores @ value), attention_scores
def forward(self, q, k, v, mask):
query = self.w_q(q)
key = self.w_k(k)
value = self.w_v(v)
# (batch, seq_len, d_model) --> (batch, seq_len, h, d_k) --> (batch, h, seq_len, d_k)
query = query.view(query.shape[0], query.shape[1], self.h, self.d_k).transpose(1, 2)
key = key.view(key.shape[0], key.shape[1], self.h, self.d_k).transpose(1, 2)
value = value.view(value.shape[0], value.shape[1], self.h, self.d_k).transpose(1, 2)
# Calculate attention
x, self.attention_scores = MultiHeadAttentionBlock.attention(query, key, value, mask, self.dropout)
# Combine all the heads together
# (batch, h, seq_len, d_k) --> (batch, seq_len, h, d_k) --> (batch, seq_len, d_model)
x = x.transpose(1, 2).contiguous().view(x.shape[0], -1, self.h * self.d_k)
# (batch, seq_len, d_model) --> (batch, seq_len, d_model)
return self.w_o(x)
In this code snippet, the constructor (init) initializes the parameters of the multi-head attention block, including the dimensionality of the model (d_model), the number of attention heads (h), and the dropout probability. It also initializes linear layers (w_q, w_k, w_v, and w_o) for transforming the input queries, keys, and values.
The attention method calculates the attention scores between the query, key, and value tensors, applying a mask if provided, and applying dropout for regularization.
In the forward method, the input query, key, and value tensors are transformed using the linear layers. Then, they are reshaped to split them into multiple heads, and the attention mechanism is applied using the attention method. Finally, the outputs from different heads are concatenated and transformed back to the original dimensionality. For better understanding, refer the following diagram
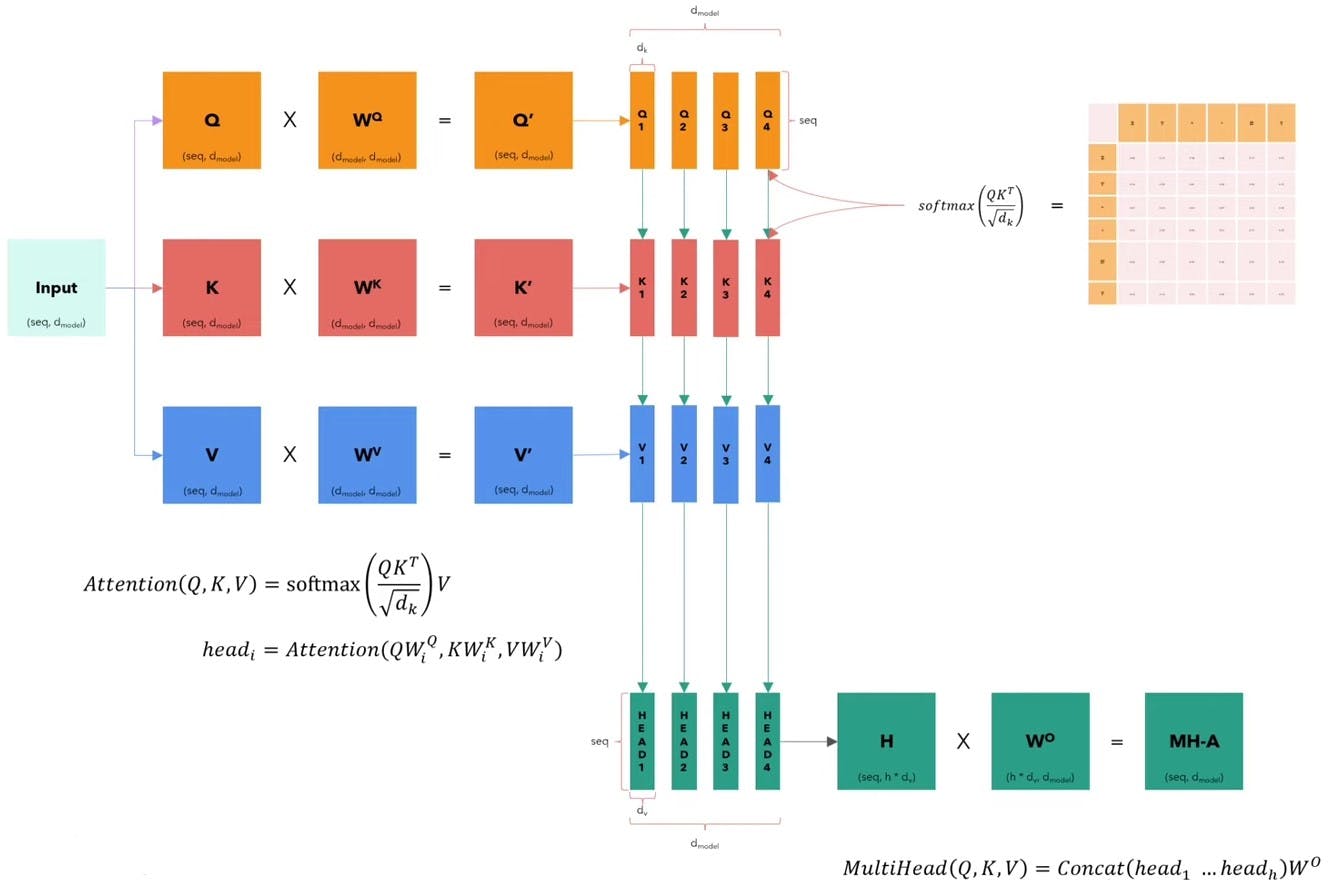
The next module that we are going to code is layer normalization.
Layer Normalization
Alright, now that we've got multi-head attention block, let's see another essential component of the Transformer model: layer normalization. The model processes data through all the different layers, sometimes the values can become a bit unbalanced. Layer normalization helps keep everything in check by standardizing the values across each layer.
This normalization step ensures that our model learns more effectively and speeds up the training process. Let's code it.
class LayerNormalization(nn.Module):
def __init__(self, features, eps:float=10**-6):
super().__init__()
self.eps = eps
self.alpha = nn.Parameter(torch.ones(features))
self.bias = nn.Parameter(torch.zeros(features))
def forward(self, x):
# x: (batch, seq_len, hidden_size)
mean = x.mean(dim = -1, keepdim = True) # (batch, seq_len, 1)
std = x.std(dim = -1, keepdim = True) # (batch, seq_len, 1)
# eps is to prevent dividing by zero or when std is very small
return self.alpha * (x - mean) / (std + self.eps) + self.bias
In this code snippet, the constructor (init) initializes the parameters of the layer normalization, including the number of features (or hidden units) and a small epsilon value (eps) to prevent division by zero. It also initializes learnable parameters alpha (scale) and bias, which are used to scale and shift the normalized values.
In the forward method, layer normalization is applied to the input tensor x. First, the mean and standard deviation are calculated along the last dimension of the input tensor. Then, the input tensor is normalized using these statistics, along with the learnable parameters alpha and bias.
The next module that we are going to code is feed forward block.
Feed Forward Block
Let's talk about another important piece of the transformer model: feed-forward block. Just like a chef in the kitchen, the feed-forward block takes the raw ingredients (input embeddings) and cooks them into something more refined and useful for our model to understand. It does this by applying a couple of linear transformations followed by a non-linear activation function. Let's code it.
class FeedForwardBlock(nn.Module):
def __init__(self, d_model, d_ff, dropout):
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
# (batch, seq_len, d_model) --> (batch, seq_len, d_ff) --> (batch, seq_len, d_model)
return self.linear_2(self.dropout(torch.relu(self.linear_1(x))))
In this code snippet, the constructor (init) initializes the parameters of the feed-forward block, including the dimensionality of the model (d_model), the dimensionality of the intermediate layer (d_ff), and the dropout probability. It also initializes two linear transformation layers (linear_1 and linear_2) and a dropout layer.
In the forward method, the input tensor x is passed through the first linear transformation (linear_1), followed by the rectified linear unit (ReLU) activation function and dropout. Then, the output is passed through the second linear transformation (linear_2) to produce the final transformed output.
Now, let's create a layer that manages the skip connections.
Residual Connections
Just like finding a shortcut on your way home, these connections helps the model learn more efficiently and prevent information loss as it passes through each layer. They're like safety nets that ensure our model retains important information while still allowing it to explore different paths to learn. Let's code it.
class ResidualConnection(nn.Module):
def __init__(self, features, dropout):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = LayerNormalization(features)
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))
In this code snippet, the constructor (init) initializes the parameters of the residual connection, including the number of features and the dropout probability. It also initializes a dropout layer and a layer normalization module.
In the forward method, the input tensor x is passed through the layer normalization module (norm), followed by the sublayer (e.g., attention or feed-forward block). The output of the sublayer is then passed through the dropout layer and added to the original input tensor x. This addition operation ensures that the original input is preserved while incorporating the output of the sublayer.
Now we need to create an encoder block which will contain one multi-head attention, two add and norm layer and one feed-forward block (refer the model architecture at top).
Encoder Block
The encoder block puts together all the components we've built so far. Let's code it.
class EncoderBlock(nn.Module):
def __init__(self, features, self_attention_block, feed_forward_block, dropout):
super().__init__()
self.self_attention_block = self_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(features, dropout) for _ in range(2)])
def forward(self, x, src_mask):
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, src_mask))
x = self.residual_connections[1](x, self.feed_forward_block)
return x
class Encoder(nn.Module):
def __init__(self, features, layers) :
super().__init__()
self.layers = layers
self.norm = LayerNormalization(features)
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
In this code, we define two classes: EncoderBlock and Encoder.
The EncoderBlock class represents a single block within the encoder. It consists of a self-attention block, a feed-forward block, and residual connections. During the forward pass, the input tensor x is passed through the self-attention block, followed by a residual connection. Then, it's passed through the feed-forward block and another residual connection. This structure allows the model to capture complex patterns and relationships within the input data effectively.
The Encoder class represents the entire encoder layer, which consists of multiple EncoderBlocks stacked on top of each other. During the forward pass, the input tensor x is passed through each EncoderBlock sequentially, with the output of each block serving as the input to the next one. Finally, layer normalization is applied to the output of the encoder layer to standardize the values across each layer.
Now we need to create a decoder block.
Decoder Block
In decoder block, the output embeddings are the same as the input embeddings. What I actually mean is that, the class that we need to define is the same. And the same goes for the positional encoding. Let's code it.
class DecoderBlock(nn.Module):
def __init__(self, features, self_attention_block, cross_attention_block, feed_forward_block, dropout):
super().__init__()
self.self_attention_block = self_attention_block
self.cross_attention_block = cross_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(features, dropout) for _ in range(3)])
def forward(self, x, encoder_output, src_mask, tgt_mask):
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, tgt_mask))
x = self.residual_connections[1](x, lambda x: self.cross_attention_block(x, encoder_output, encoder_output, src_mask))
x = self.residual_connections[2](x, self.feed_forward_block)
return x
class Decoder(nn.Module):
def __init__(self, features, layers):
super().__init__()
self.layers = layers
self.norm = LayerNormalization(features)
def forward(self, x, encoder_output, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, encoder_output, src_mask, tgt_mask)
return self.norm(x)
In this code, we define two classes: DecoderBlock and Decoder.
The DecoderBlock class represents a single block within the decoder. It consists of three main components: a self-attention block, a cross-attention block, a feed-forward block, and residual connections. During the forward pass, the input tensor x is passed through the self-attention block, followed by a residual connection. Then, it's passed through the cross-attention block, where it attends to the encoder output, and another residual connection. Finally, it's passed through the feed-forward block and a final residual connection. This structure allows the model to generate output sequences based on both the encoder output and previously generated tokens.
The Decoder class represents the entire decoder layer, which consists of multiple DecoderBlocks stacked on top of each other. During the forward pass, the input tensor x is passed through each DecoderBlock sequentially, with the output of each block serving as the input to the next one. Finally, layer normalization is applied to the output of the decoder layer to standardize the values across each layer.
The last layer that we need is the linear layer.
Linear Layer
We've built the core components of our Transformer model, but there's one more piece left: the linear layer. After all the hard work our model has done processing and understanding the input data, the linear layer helps map those learned representations to the actual output we desire. Let's code it.
class LinearLayer(nn.Module):
def __init__(self, d_model, vocab_size):
super().__init__()
self.proj = nn.Linear(d_model, vocab_size)
def forward(self, x) -> None:
# (batch, seq_len, d_model) --> (batch, seq_len, vocab_size)
return self.proj(x)
In this code snippet, the constructor (init) initializes the parameters of the linear layer, including the dimensionality of the model (d_model) and the size of the vocabulary (vocab_size). It also initializes a linear transformation layer (proj) that maps the input tensor to the vocabulary space.
In the forward method, the input tensor x, representing the learned representations from the decoder, is passed through the linear transformation layer. This produces an output tensor with shape (batch, seq_len, vocab_size), where seq_len represents the sequence length and vocab_size represents the size of the vocabulary.
Now, let's define the transformer block.
Transformer Block
class Transformer(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, src_pos, tgt_pos, linear_layer):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.src_pos = src_pos
self.tgt_pos = tgt_pos
self.linear_layer = linear_layer
def encode(self, src, src_mask):
# (batch, seq_len, d_model)
src = self.src_embed(src)
src = self.src_pos(src)
return self.encoder(src, src_mask)
def decode(self, encoder_output, src_mask, tgt, tgt_mask):
# (batch, seq_len, d_model)
tgt = self.tgt_embed(tgt)
tgt = self.tgt_pos(tgt)
return self.decoder(tgt, encoder_output, src_mask, tgt_mask)
def project(self, x):
# (batch, seq_len, vocab_size)
return self.linear_layer(x)
def build_transformer(src_vocab_size, tgt_vocab_size, src_seq_len, tgt_seq_len, d_model: int=512, N: int=6, h: int=8, dropout: float=0.1, d_ff: int=2048):
# Create the embedding layers
src_embed = InputEmbeddings(d_model, src_vocab_size)
tgt_embed = InputEmbeddings(d_model, tgt_vocab_size)
# Create the positional encoding layers
src_pos = PositionalEncoding(d_model, src_seq_len, dropout)
tgt_pos = PositionalEncoding(d_model, tgt_seq_len, dropout)
# Create the encoder blocks
encoder_blocks = []
for _ in range(N):
encoder_self_attention_block = MultiHeadAttentionBlock(d_model, h, dropout)
feed_forward_block = FeedForwardBlock(d_model, d_ff, dropout)
encoder_block = EncoderBlock(d_model, encoder_self_attention_block, feed_forward_block, dropout)
encoder_blocks.append(encoder_block)
# Create the decoder blocks
decoder_blocks = []
for _ in range(N):
decoder_self_attention_block = MultiHeadAttentionBlock(d_model, h, dropout)
decoder_cross_attention_block = MultiHeadAttentionBlock(d_model, h, dropout)
feed_forward_block = FeedForwardBlock(d_model, d_ff, dropout)
decoder_block = DecoderBlock(d_model, decoder_self_attention_block, decoder_cross_attention_block, feed_forward_block, dropout)
decoder_blocks.append(decoder_block)
# Create the encoder and decoder
encoder = Encoder(d_model, nn.ModuleList(encoder_blocks))
decoder = Decoder(d_model, nn.ModuleList(decoder_blocks))
# Create the linear layer
linear_layer = LinearLayer(d_model, tgt_vocab_size)
# Create the transformer
transformer = Transformer(encoder, decoder, src_embed, tgt_embed, src_pos, tgt_pos, linear_layer)
# Initialize the parameters
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return transformer
The Transformer class has methods for encoding, decoding, and projecting. The encode method takes the source input and source mask, applies input embeddings and positional encodings, and passes them through the encoder. The decode method takes the encoder output, source mask, target input, and target mask, applies input embeddings and positional encodings to the target input, and passes them through the decoder. The project method takes the decoder output and passes it through the linear layer to produce the final output.
The build_transformer function is a utility function to construct a Transformer model. It creates input embeddings, positional encodings, encoder blocks, decoder blocks, encoder, decoder, and linear layer based on the provided parameters such as vocabulary sizes, sequence lengths, model dimensions, number of layers, number of attention heads, and dropout rate.
Conclusion
In conclusion, this tutorial showcased how to build a Transformer model using PyTorch. Transformers, with their ability to handle long-term dependencies and parallel processing, offer great potential in various fields, especially in tasks like language translation, summarization, and sentiment analysis.